TL;DR - Sam Altman's IQ vs. Model 'IQs'
Let's cut through the noise fast. Sam Altman's actual IQ isn't public, and there's no verified, official number anywhere. Plenty of blogs toss around guesses, but they don't cite real test results. Meanwhile, model trackers publish "IQ-style" scores for AI systems, which are fun to compare but not the full story for picking tools or judging leaders.
- There's no verified, public IQ score for Sam Altman. Online numbers are rumors.
- Trackers publish "IQ-style" scores for models, but methods and tests vary a lot.
- We include a playful CEO ranking, clearly labeled as speculation based on public achievements.
- For buying tools or agents, judge by real benchmarks, cost, latency, and fit, not just "IQ".
For the record, the lack of a verified Sam Altman IQ has been noted by others as well. See the discussion in "What is Sam Altman's IQ?" for context and caveats (AI Blog). And for model "IQ" numbers referenced below, check the public tracker at Tracking AI.
What Do We Actually Know About Sam Altman's IQ?
Short answer, nothing official. There isn't a verified IQ score for Sam Altman. Claims online range from 150+ to 170, but they have no primary source. No test scan. No credible confirmation. Just speculation. That's it.
Why does this matter? Because IQ bait gets clicks. It also reduces complex leadership to a single number. That's lazy. If you want a clearer signal of someone's ability, follow the track record: product milestones, capital raised, hiring quality, dealmaking, and ecosystem impact. On those fronts, Sam's resume is obvious: OpenAI's product runs, huge partnerships, and a surge of AI-native startups building on the stack.
For context, one speech-analysis ranking placed Sam Altman above Elon Musk and Mark Zuckerberg, and scored Demis Hassabis at the top in the U.S. CEO set. The method reviewed public speeches for markers like logical reasoning and abstract thinking. It's an interesting lens, not a clinical IQ test. Use it as a soft signal, not a final verdict.
A Playful (Speculative) Power Ranking of AI CEOs by 'IQ-ish' Signals
Let's have some fun, but keep it honest. This is opinion, not test data. I'm ranking based on public achievements, research depth, and "solve hard problems" energy. You'll disagree, and that's fine. The point is to compare patterns, not pretend we have their private test scores.
1) Demis Hassabis
Demis is the brain behind DeepMind's greatest hits: AlphaGo, AlphaZero, and AlphaFold. He was a child chess prodigy and has published serious research. If I had to bet on who would ace reasoning and pattern discovery, it's Demis. The combination of research leadership, cross-disciplinary teams, and repeated breakthroughs is rare. He's the clear number one on "IQ-ish" signals for me.
- Breakthroughs, not just products: AlphaGo changed how we think about search and strategy. AlphaFold cracked protein folding at scale.
- Deep science mindset: Builds programs that push the frontier, not just ship features.
- Speech-analysis lists have put him first in the U.S. CEO pool for reasoning signals from public talks.
2) Dario Amodei
Dario brings research-first rigor to Anthropic. He's steeped in safety and alignment work, and Anthropic's pace has been impressive. If you care about careful scaling and controllability, Dario's playbook looks strong. His profile reads like a builder who sees failure modes early and still ships.
- Deep research chops: Long history in AI safety and system behavior.
- Steady product curve: Rapid capability growth with constant attention to guardrails.
- "Strong analytical depth" is written all over Anthropic's releases and research notes.
3) Elon Musk
Elon is a force of nature. SpaceX, Tesla, rockets, batteries, chips, autonomy. Wild bets, many pay off. He also courts chaos and controversy. If the measure is raw systems thinking across domains, he scores high. If the measure is stable execution in AI labs, it's more complicated.
- Multi-industry bets: Aerospace, auto, energy, robotics.
- High variance: World-class engineering wins and very public misses.
- Speech-analysis rankings have him mid-pack, which tracks with the volatility.
4) Sam Altman
Sam is an operator and ecosystem builder. He spots talent, aligns capital, and sets aggressive product tempo. You can't measure that in an IQ test. But it's priceless in a fast-moving market. He's also been the face of AI to governments and the press, which is not easy, and not a "score" on any exam.
- Track record: OpenAI product waves, massive partnerships, and distribution.
- Capital and talent: Pulls resources, then points them at the right problems.
- Speech-analysis lists place him above Elon. It fits his measured, persuasive style.
None of this turns into a neat number. That's the point. Complex leadership skill beats any single metric.
Model 'IQ' Scores: How Today's Flagships Compare
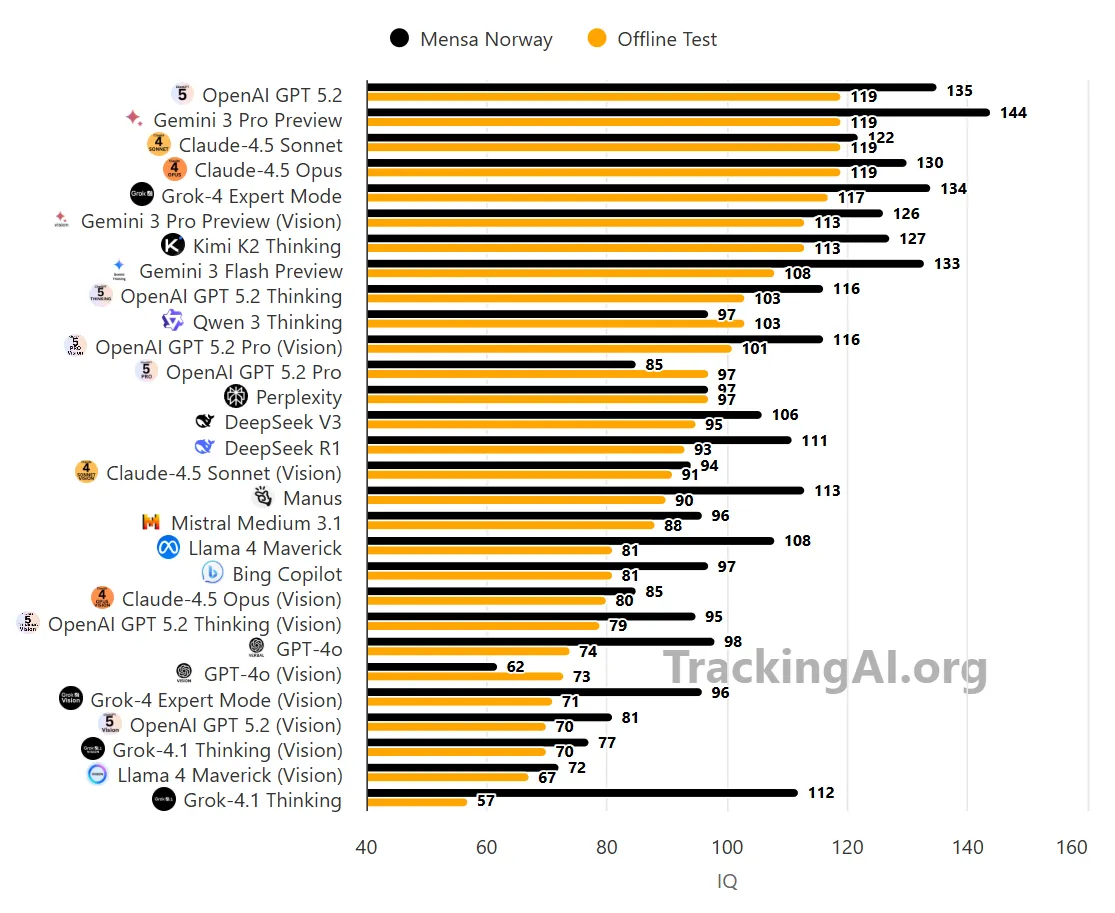
Now let's talk about models. Trackers publish "IQ-style" scores to give a human-friendly shorthand for reasoning ability. Helpful, with a big caveat. These are not clinical IQ tests. Methods, question pools, and possible leakage differ across trackers. Use the numbers as rough signals, then test models on your real tasks.
Here's a snapshot of publicly reported "IQ-style" scores for popular models right now, as listed by public trackers. Gemini 3 Pro sits near the top. GPT-class models are close behind. Grok 4 Expert posts a strong score. Gemini Flash 3 Preview overachieves for a cheaper model. GPT-4.5 Opus trails on this metric but may punch above its weight on coding and agentic tasks.
| Feature | Tool A | Tool B | Tool C |
|---|---|---|---|
| Gemini 3 Pro | 144 | High reasoning score on public tracker | 1st |
| GPT 5.2 | 135 | Strong generalist performance | 2nd |
| Grok 4 Expert | 134 | Competitive on reasoning tasks | 3rd |
| Gemini Flash 3 Preview | 133 | Cheaper, fast, still high "IQ" score | 4th |
| GPT‑4.5 Opus | 130 | Often strong instincts on coding | 5th |
Source for these reported numbers: public tracker listings at Tracking AI. The point isn't to crown a single winner. It's to build a mental model for what "IQ-style" numbers can and can't tell you. A model that scores lower here can still beat others on coding or tool use. That happens a lot.
Also worth noting, some write-ups have highlighted other tracked results, like OpenAI's o1 model logging an IQ-style score around 120 on one test and outperforming a big chunk of humans. Again, interesting, but context matters. Different tests, different rules, different leakage risks. Keep your salt handy.
IQ Isn't Everything, for People or Models
I like simple numbers. They're clean. But they miss the messy parts that drive outcomes. Leaders and models win for different reasons than a single metric can capture.
For human leaders
- Vision and focus: Saying no to 100 good ideas to ship 1 great one.
- Execution: Hiring, culture, deadlines, and iteration speed.
- Persuasion: Fundraising, partnerships, public trust.
- Risk calibration: Knowing when to push and when to pause.
- Product taste: Feeling what users want before they say it.
For models and agents
- Reasoning: Generalization across domains is key, but it's only one piece.
- Coding: Look at HumanEval, SWE-bench, and repo-level tasks, not just toy problems.
- Knowledge and tools: Web search, code execution, and function calling change the curve.
- Memory and planning: Long-horizon tasks and multi-step plans are what agents live on.
- Real-world ops: Latency, cost per task, rate limits, privacy, and SOC2-level controls.
Here's the truth nobody loves to hear. Two models with similar "IQ-style" scores can diverge wildly in production. Tooling can carry a model. So can a good agent framework. So can retrieval. If you're choosing for business impact, measure end-to-end throughput, not just a test badge.
How to Choose AI Agents That Actually Help Your Business
Don't chase a leaderboard number. Solve your job to be done. Here's a tight playbook that works.
- Define the job: content ops, lead gen, coding, research, or support. Pick one.
- Map tasks to benchmarks: coding tasks to SWE-bench, reasoning to MMLU-style, support to deflection and CSAT.
- Run side-by-side pilots: same prompts, same datasets, same SOPs. Time it.
- Score output quality: accuracy, style fit, and error rate on real samples.
- Track the economics: cost per task, latency, and failure recovery cost.
- Check agent features: memory, tool use, multi-step planning, autonomy controls.
- Demand observability: logs, traces, and replay for root-cause analysis.
- Plan scale: rate limits, concurrency, data governance, and vendor lock-in.
What I'd actually do this quarter
- Pick one workflow that burns time every week. Make it measurable.
- Trial 2-3 agents on that workflow with the same prompts and data.
- Set a target: 50 percent time saved or a 20 percent quality lift.
- Pick the winner and then automate the next adjacent workflow.
We publish curated picks of agent tools built for real work. When you're ready to move past "IQ" screenshots and into compounding time savings, that's where to go next.
Sources and Notes
On Sam Altman's IQ, there's no verified public score. This has been noted in a public explainer which also flags the rumor problem and why it's not a good decision signal (AI Blog). For model "IQ" numbers, see the public listing at Tracking AI. Speech-analysis lists have ranked Demis Hassabis at the top in the U.S. CEO group and placed Sam Altman above Elon Musk; interesting, but not a clinical IQ measurement.